・Anthropic が 2026 年 6 月 9 日、Opus 級を超える「ミュトス級」モデルを一般向けに安全化した Claude Fable 5 を公開した。同社が一般提供するモデルとしては過去最強となる。
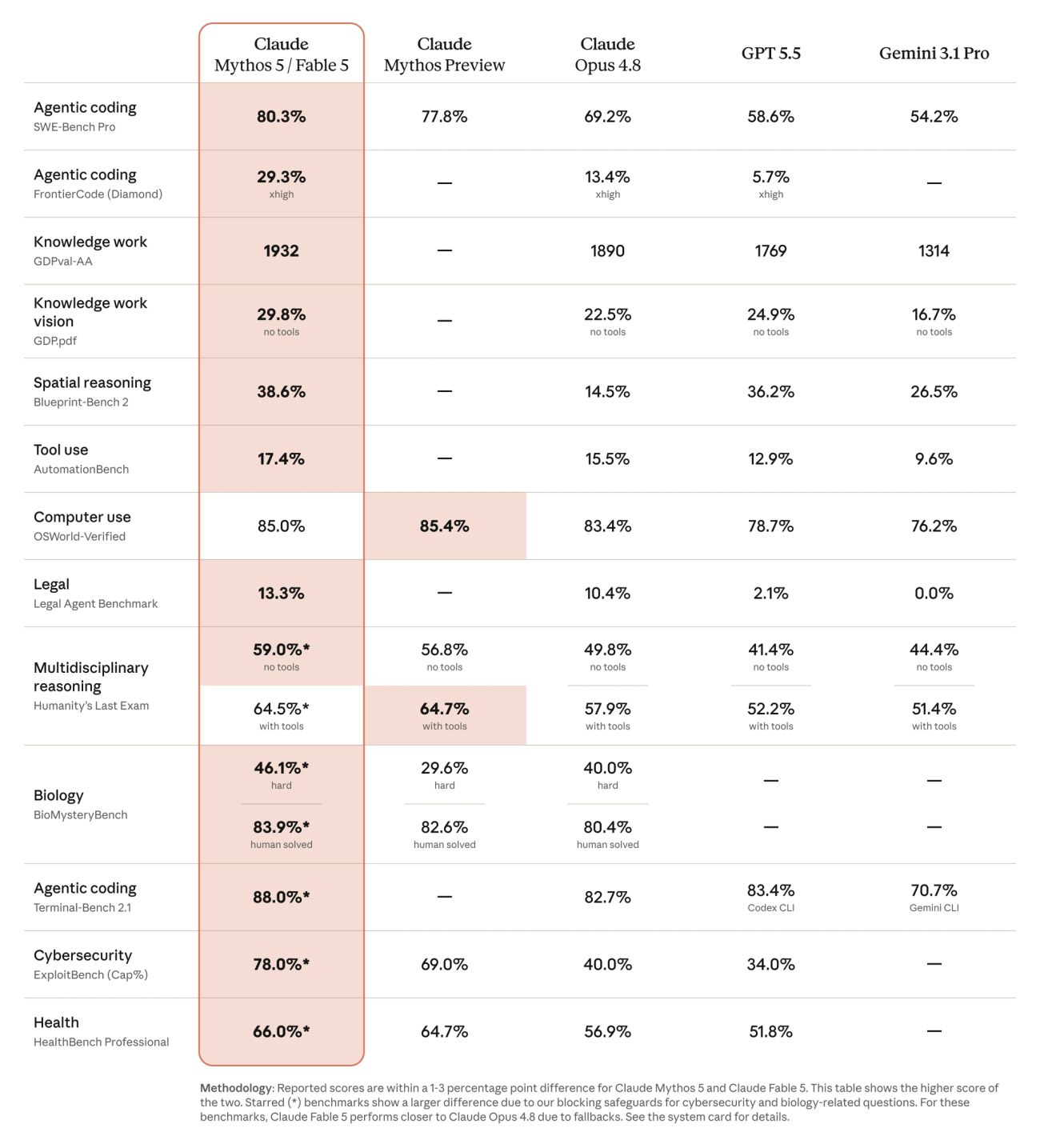
・公式ベンチマークでは SWE-Bench Pro 80.3%(Opus 4.8 は 69.2%、GPT-5.5 は 58.6%)などほぼ全項目で最先端。料金は入力 $10 / 出力 $50(100万トークンあたり)。
・6 月 22 日まで Pro / Max / Team / Enterprise(シート型)プランに追加費用なしで含まれる。一部の高リスク領域の質問は自動的に Claude Opus 4.8 が応答する「安全ルーティング」を初めて搭載した。
2026 年 6 月 9 日、Anthropic は同社史上もっとも強力な一般提供モデル Claude Fable 5 を公開した。これまで政府機関や限られたパートナーにしか提供されていなかった「ミュトス級(Mythos-class)」の能力が、ついに誰でも使える形で開放されたことになる。本記事では、公式発表の事実をベースに「何がどれだけ強いのか」「いくらで使えるのか」「安全ルーティングとは何か」を、AI を使う側の目線で整理する。
一言で定義すると、Claude Fable 5 は「Opus 級の上に新設された能力階層『ミュトス級』のモデルを、一般利用向けに安全化したもの」だ。Anthropic のモデル階層はこれまで Haiku(軽量)→ Sonnet(中位)→ Opus(最上位)だったが、2026 年に入り Opus を超える Mythos 級が登場。その最初の一般提供版が Fable 5 という位置づけになる。
同時発表の Claude Mythos 5 は同じ基盤モデルから一部の安全制限を外したバージョンで、米国政府と連携するサイバー防御プログラム「Project Glasswing」のパートナーなど、審査された組織だけが利用できる。つまり「中身は同じ系統、開放範囲が違う」という二段構えだ。
これまで「研究機関・政府向けの最強モデル」と「一般向けの実用モデル」は別物だった。Fable 5 はその壁を取り払い、最強クラスの能力に安全装置を付けて一般開放した初のケース。AI を使う側にとっては「上限性能」が一段引き上がったことを意味する。
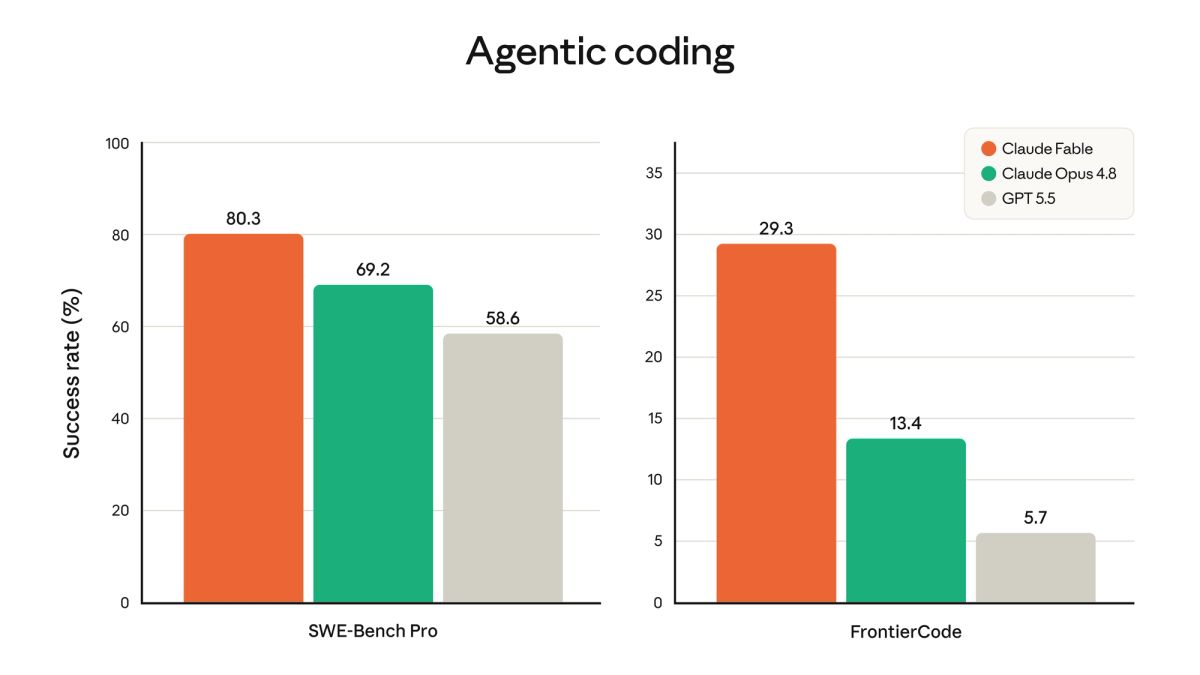
Anthropic が公開した公式ベンチマークによれば、Fable 5(Mythos 5 と 1〜3 ポイント差以内)は試験したほぼすべての項目で最高水準に達した。特に差が大きいのがコーディング領域だ。SWE-Bench Pro で 80.3%(Opus 4.8: 69.2%、GPT-5.5: 58.6%、Gemini 3.1 Pro: 54.2%)、難問揃いの FrontierCode (Diamond) では 29.3% と、2 位の Opus 4.8(13.4%)の 2 倍以上のスコアを記録している。
タスクが長く複雑になるほど他モデルとの差が開く、というのが公式の説明だ。ターミナル操作の Terminal-Bench 2.1 で 88.0%(GPT-5.5 + Codex CLI: 83.4%、Gemini CLI: 70.7%)、人類最難関の総合試験と呼ばれる Humanity's Last Exam(ツールあり)で 64.5% という数字は、エージェント的な長時間作業での実力を示している。
・SWE-Bench Pro: 80.3% — エージェント的コーディングの代表指標で首位
・OSWorld-Verified: 85.0% — PC 操作(コンピュータユース)でも最高水準
・GDPval-AA: 1932 — 実務的なナレッジワークの評価で Opus 4.8(1890)、GPT-5.5(1769)を上回る
・外部レッドチームによる1,000 時間超のテストで、普遍的なジェイルブレイクは発見されず(公式発表)
Fable 5 の最大の特徴は性能ではなく、「安全ルーティング」という新しい安全機構を初めて製品に組み込んだことかもしれない。仕組みはこうだ。ユーザーの質問を分類器が常時チェックし、サイバーセキュリティ・生物/化学・モデル蒸留(能力の抜き取り)に関わる高リスクな内容と判定された場合、Fable 5 ではなく一段階安全側の Claude Opus 4.8 が代わりに応答する。
公式によれば、この振り分けは保守的に調整されており、発動するのはセッション全体の 5% 未満。日常の利用ではほぼ意識することはない。前述のベンチマーク表で一部項目に * 印が付いているのは、このフォールバックの影響で Fable 5 のスコアが Opus 4.8 寄りになるためで、公式が制約込みの数字を明示している点は透明性が高い。
API 料金は入力 100 万トークンあたり $10、出力 100 万トークンあたり $50。Opus 級の従来価格帯に対して、ミュトス級の能力がこの水準で開放されたことになる。さらに注目すべきは無料期間だ。6 月 9 日〜22 日の 2 週間、Pro / Max / Team / シート型 Enterprise プランでは追加費用なしで Fable 5 を利用できる。23 日以降はクレジット購入が必要になり、容量が確保され次第サブスクリプションプランへの常設復帰が予定されている。
提供チャネルも初日から広い。Claude アプリ・Claude API に加えて、Amazon Bedrock でも同日から利用可能になっており、企業システムへの組み込みも最初から想定されている。
(5分) Pro / Max プランの人は、モデル選択から Fable 5 を選んで普段の質問をひとつ投げてみる。6 月 22 日まで追加費用なしなので試すなら今週。
(15分) 普段 Opus 4.8 や GPT-5.5 でやっている定番タスク(コードレビュー、長文要約など)を同じプロンプトで Fable 5 に投げ、差分を体感する。
(30分) API 利用者はモデル ID を切り替えて手元の評価セットを再実行。$10/$50 の単価で自分のワークロードのコストを試算しておく。
同時発表の Claude Mythos 5 は、生物学関連のセーフガードを外した(サイバー領域の制限は維持)バージョンで、世界最強クラスのサイバーセキュリティ能力を持つとされる。提供先は米国政府と連携する Project Glasswing のパートナー(サイバー防御組織)に限定され、今後、審査制で生物学研究者向けのアクセスプログラムも開始予定だ。タンパク質設計のタスクでは専門家と同等以上の性能を示したという。
つまり Anthropic は「全部を開放する」のではなく、能力のどこまでを誰に開くかを段階設計した。Fable 5 の一般公開は、その設計思想がはじめて大規模に試される場でもある。
本記事の数値・条件は 2026 年 6 月 12 日時点の公式発表・報道ベースです。無料期間や提供条件は変更される可能性があるため、利用前に必ず Anthropic 公式の最新情報を確認してください。また「ミュトス級」の能力評価はベンチマークに基づくものであり、すべての実務タスクでの優位を保証するものではありません。
このリリースは、Anthropic が IPO 準備を進めていると報じられた直後というタイミングで行われた。Bloomberg Television も「IPO を控えた Anthropic がミュトス級モデルを公開」として市場の視点から取り上げている。評価額約 1 兆ドルと報じられる同社にとって、最強モデルの一般開放は技術発表であると同時に、公開市場へのショーケースでもある。
IPO の経緯と業界の資本競争については、姉妹記事 「Anthropic、IPOへ — "仕事を進めるAI"が公開市場で評価される日」 で詳しく整理している。あわせて読むと、今回のリリースの戦略的な位置づけが立体的に見えるはずだ。
| 項目 | Claude Fable 5 | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-Bench Pro(コーディング) | 80.3% | 69.2% | 58.6% | 54.2% |
| FrontierCode Diamond | 29.3% | 13.4% | 5.7% | — |
| OSWorld-Verified(PC操作) | 85.0% | 83.4% | 78.7% | 76.2% |
| Humanity's Last Exam(ツールあり) | 64.5% | 57.9% | 52.2% | 51.4% |
| API価格(入力/出力 per 1M tok) | $10 / $50 | —(公式表記参照) | —(公式表記参照) | —(公式表記参照) |
数値は Anthropic 公式発表(2026年6月9日)のベンチマーク表より。他社価格は変動があるため各社公式ページを参照。
筆者がもっとも重要だと考えるのは、ベンチマークの数字よりも「危険な能力を持つモデルを、削るのではなくルーティングで包んで出した」という製品設計の選択だ。従来の安全化は能力自体を訓練で抑える方式が主流で、その分性能も犠牲になっていた。Fable 5 は能力を保持したまま、リスク領域だけ別モデルに迂回させる。安全性をモデルの内部ではなくシステムのアーキテクチャで担保する方向への転換であり、これは今後の業界標準になり得る。
もうひとつ評価したいのは、フォールバックの影響を受けるベンチマークに * 印を付けて公開した透明性だ。一方で、ルーティングの判定基準そのものはブラックボックスであり、「どこまでが高リスクか」を一企業が決める構図には議論の余地がある。無料期間は実質的な大規模公開ベータでもあり、6 月 23 日以降にどんな運用調整が入るかが、この設計思想の成否を測る最初の試金石になると筆者は見ている。
① 無料期間を逃さない — Pro / Max ユーザーは 6 月 22 日までに普段のワークフローで試し、自分のタスクでの体感差をメモしておく。
② 「いつものプロンプト」で比較する — 新モデル評価は特別な難問より、日常タスクの再現性で測るほうが実用的な判断ができる。
③ ルーティングの挙動を知っておく — セキュリティや生物学関連の業務で使う場合は、応答が Opus 4.8 にフォールバックする可能性を前提に検証する。
本記事は教育・情報提供を目的としています。記載の数値・条件は 2026 年 6 月 12 日時点の公式発表・報道に基づきます。AI 技術は急速に変化するため、最新情報は必ず公式ソースをご確認ください。図表画像の著作権は Anthropic に帰属します(報道・解説目的での引用)。